How to Fix “Google Crawled Currently Not Indexed” Issue: A Comprehensive Guide

For website proprietors and SEO enthusiasts, the irksome encounter of search engines successfully crawling but withholding the indexing of pages is all too familiar. This setback, a potential roadblock to visibility and organic traffic, demands our attention. This article aims to dissect the “Google Crawled Currently Not Indexed” predicament, shedding light on its causation, and equip you with actionable remedies. Let’s commence our exploration.
Search engines, like Google, use a process known as crawling and indexing to discover and organize web content. However, it’s not uncommon to encounter the situation where your website’s pages are crawled but not indexed, leading to a decrease in your online visibility.
Understanding Crawling and Indexing
In the vast realm of the internet, search engines play a crucial role in helping users find relevant information. The process of crawling and indexing is at the core of how search engines like Google, Bing, and Yahoo organize and present this information to users. Let’s delve deeper into the mechanics of crawling and indexing to gain a comprehensive understanding.
What is Crawling?
Crawling is the first step in the search engine process. Think of it as the exploration phase where search engine bots, also known as spiders or crawlers, traverse the interconnected web of pages. These bots start their journey by visiting a handful of websites and then methodically follow links from those pages to other sites. This creates a massive network of interconnected web pages that search engines can navigate through.
During the crawling process, these bots analyze not only the content of the pages but also the links present on those pages. This link analysis helps them discover new pages and revisit existing ones. However, it’s important to note that not all pages on the internet are crawled. Factors like the authority and relevance of a website influence how frequently and deeply search engine bots crawl it.
The Significance of Indexing
Once the crawling bots have explored the web and collected information from various pages, the next step is indexing. Indexing involves organizing and storing the gathered information in a structured manner within the search engine’s database. This database, often referred to as the index, serves as a vast library containing information about billions of web pages.
When a user enters a query into a search engine, the search engine doesn’t actually search the internet in real-time. Instead, it searches its indexed database to provide relevant results quickly. This is where the indexing process becomes crucial. Each indexed page is associated with various attributes such as keywords, content, meta information, and more. These attributes collectively determine how and when a page will appear in search engine results.
The Complexity of Indexing
While the concept of indexing might seem straightforward, the actual process is far more complex. Search engines use sophisticated algorithms to assess the quality and relevance of web pages. They consider factors like the uniqueness and usefulness of content, the authority of the website, the number and quality of incoming links, and even user behavior and engagement metrics.
Furthermore, indexing is not a one-time event. The web is dynamic, with new pages being created and existing ones changing constantly. As a result, search engines continuously crawl and re-index websites to ensure that their results remain up-to-date and relevant. This dynamic nature of indexing also means that webmasters need to maintain their websites and keep their content fresh to maintain or improve their search engine rankings.
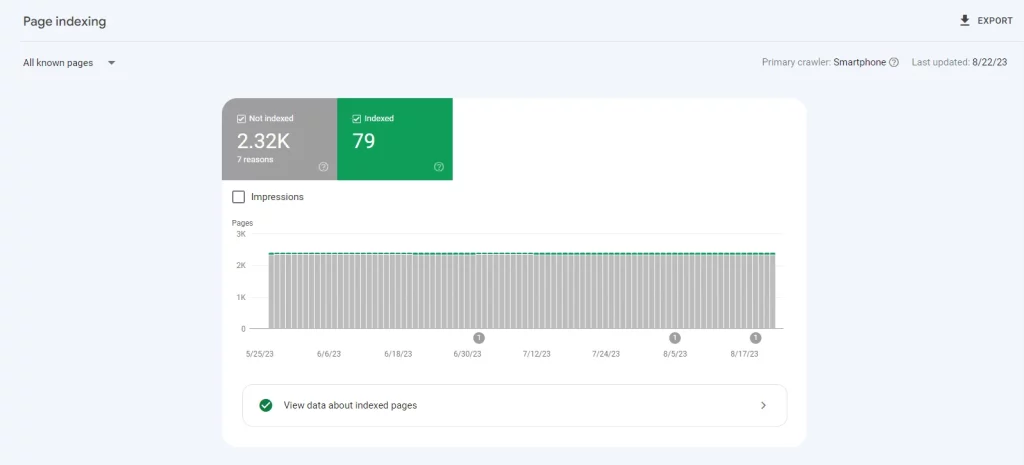
Common Reasons for the Issue: Google Crawled Currently Not Indexed
When delving into the intricate realm of website visibility and search engine performance, certain recurrent factors emerge as culprits behind the “Google Crawled Currently Not Indexed” quandary. Understanding these factors is pivotal to resolving the issue and reclaiming the potential benefits of indexed pages. Let’s unravel the common culprits:
-
Server Glitches: Hindrances to Accessibility
At times, the issue stems from the underlying infrastructure – your server. If the server exhibits sluggish response times or intermittent downtimes, it can impede the seamless interaction between search engine crawlers and your website. This can lead to incomplete crawling and subsequent non-indexing.
-
Robots.txt Conundrums: The Power of Disallowance
The "robots.txt" file, while essential for guiding search engine bots, can inadvertently lead to unintended consequences. Pages or directories inadvertently disallowed in this file might be excluded from indexing, limiting their visibility on search engine result pages.
-
Noindex Tags: The Exclusion Directive
Certain pages are intentionally assigned a "noindex" meta tag, signaling search engines to exclude them from indexing. While valuable for non-essential pages like terms of service or privacy policies, improper implementation can inadvertently affect crucial content.
-
Canonical Confusion: Duplication Dilemmas
Canonical tags play a crucial role in guiding search engines to the preferred version of a page when duplicate content exists. Yet, mismanaged canonical tags can trigger confusion, leading to partial or non-indexing of desired pages.
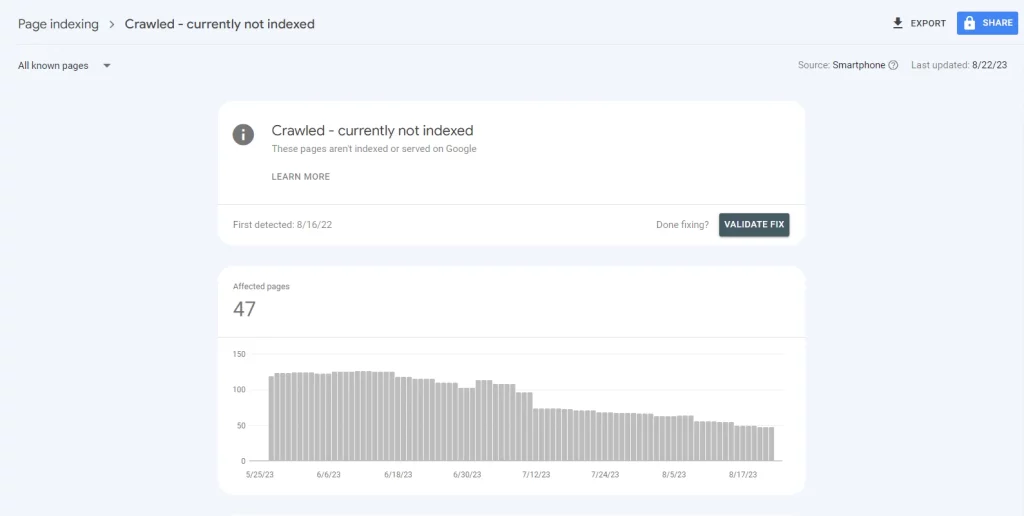
Detecting the Problem: Unveiling the Veil
In the labyrinthine landscape of website optimization, the first step towards resolution is to accurately diagnose the issue at hand. The enigma of “Google Crawled Currently Not Indexed” demands a strategic approach to detection. Here, we unveil the methods and tools to lift the veil on this perplexing situation:
-
Google Search Console: The Sentinel of Insights
Enlisting the aid of Google Search Console serves as a beacon of illumination. This indispensable tool provides a comprehensive overview of how Googlebot interacts with your website. It unveils crawl errors and indexing issues that might lie beneath the surface, allowing for informed decision-making.
-
Site:Search: The Search Engine Inquiry
A simple yet effective tactic involves a "site:yourwebsite.com" search query on a search engine. If specific pages fail to materialize in the results, it's an indicator of potential non-indexing. This uncomplicated approach can provide a quick gauge of your website's indexed status.
-
SEO Crawling Tools: The In-Depth Probes
Leveraging the prowess of third-party SEO crawling tools amplifies your detective prowess. These tools offer comprehensive reports on indexing anomalies and other technical discrepancies. By utilizing these tools, you extend your scope beyond conventional means.
The essence of detection lies in these strategic methodologies. Armed with insights from Google Search Console, the simplicity of a site:search, and the depth of SEO crawling tools, you’re poised to uncover the lurking causes behind the “Google Crawled Currently Not Indexed” predicament. This precise identification propels us towards the realm of resolution and restoration.
Resolving the Issue: Google Crawled Currently Not Indexed
With the mystery unveiled and the culprits identified, the time has come to embark on the journey of rectification. The challenge of “Crawled – Currently Not Indexed” demands meticulous and strategic actions to pave the path to resolution. Here, we present the navigational steps to address this conundrum:
-
Checking Your Server: Ensuring Smooth Passage
The foundation of your website's interaction with search engine bots lies in the server's performance. Verifying optimal server functionality is paramount. Smooth response times and minimal downtime bolster the seamless interaction between crawlers and your website, facilitating complete indexing.
-
Reviewing Robots.txt: Guiding Bots Intelligently
A careful review of your website's "robots.txt" file is pivotal. Ensuring that essential pages aren't inadvertently disallowed can prevent unnecessary barriers to indexing. A thoughtful curation of this file directs search engine bots intelligently, maximizing the reach of your content.
-
Examining Meta Robots Tags: Unmasking the Noindex
Delving into your pages' meta robots tags is essential. Eliminating the presence of the "noindex" tag from pages you wish to be indexed is vital. This corrective action ensures that your valuable content is granted the visibility it deserves in search engine results.
-
Verifying Canonical Tags: Harmonizing Content
Canonical tags, designed to address duplicate content, require meticulous attention. Ensuring their proper implementation avoids confusion and misdirection, bolstering the probability of complete indexing. By harmonizing content versions, you mitigate potential indexing gaps.
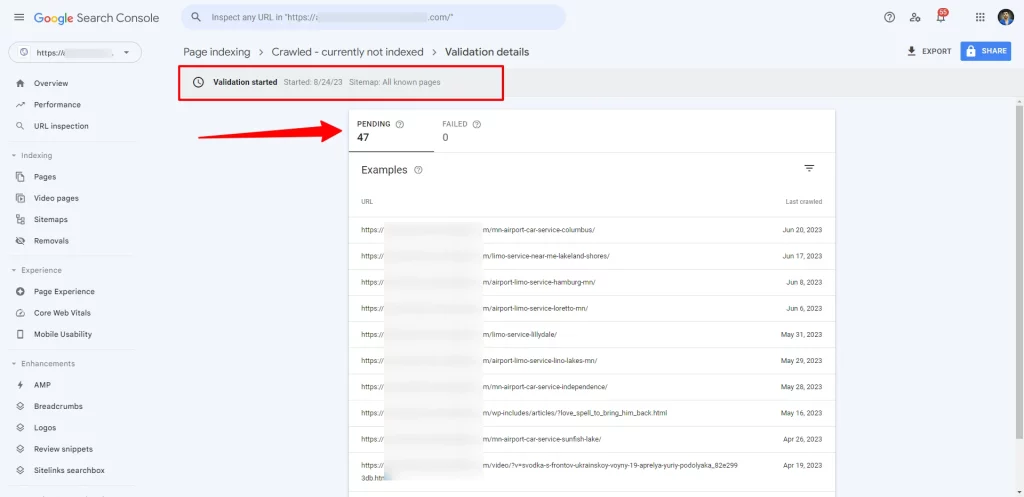
Fetching and Rendering: Expediting the Indexing Process
In our quest to conquer the “Crawled – Currently Not Indexed” dilemma, we venture into a realm of proactive measures that can expedite the indexing of your web pages. This phase revolves around the concepts of fetching and rendering, leveraging the resources at hand to ensure efficient interaction with search engines. Let’s navigate through this pivotal phase:
1. Google Search Console: The Catalyst for Indexing
Engaging with Google Search Console becomes pivotal in this juncture. Within this platform lies the power to request indexing for specific URLs. This action acts as a catalyst, propelling the relevant pages into the indexing queue and accelerating their appearance in search engine results.
2. Manual URL Submission: Directing Attention
Another strategy involves manual submission of individual URLs to search engines. By directly presenting URLs for indexing, you steer the attention of search engine bots towards specific content, amplifying the likelihood of inclusion in search results.
Through these strategic maneuvers, we transcend mere passive waiting and embrace proactive engagement. By harnessing the potential of Google Search Console and taking charge of manual URL submissions, we march towards the realm of expedited indexing. This phase amplifies our control over the process and empowers us with the tools to enhance the visibility of our content.
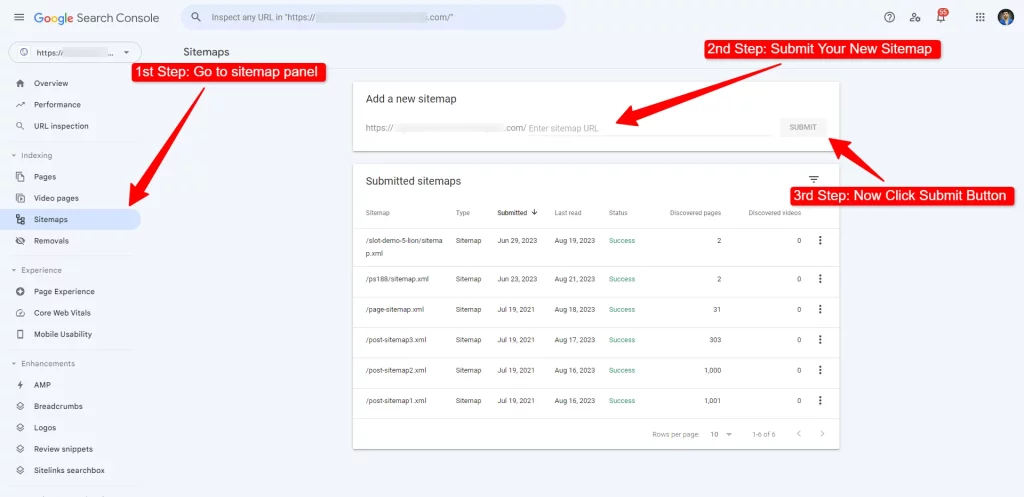
Updating Your Sitemap: Guiding Search Engines
In the intricate dance of web optimization, your sitemap plays a pivotal role. Think of it as a roadmap for search engine crawlers, guiding them to your content’s doorsteps. Here’s why keeping your sitemap updated matters:
Navigation Blueprint:
Your sitemap is like a GPS for search engine bots. It outlines the layout of your website, helping crawlers navigate through your pages efficiently and thoroughly.
Embrace Dynamism:
Digital landscapes evolve, and your sitemap should keep up. Regular updates ensure that new content gets discovered swiftly, enhancing your chances of timely indexing.
Submit for Visibility:
Share your updated sitemap with search engines, like through Google Search Console. This proactive step invites crawlers to explore your content, fostering accessibility and accuracy.
Requesting Indexing: Initiating the Inclusion
In the realm of rectifying the “Crawled – Currently Not Indexed” scenario, proactive engagement takes center stage. Having resolved underlying issues and optimized content, the final stride involves formally requesting search engines to include your updated pages in their index. Let’s delve into this pivotal phase:
- Google Search Console: Leveraging Google Search Console, you can formally appeal for indexing of specific URLs. This step communicates your readiness for inclusion and propels your pages to the forefront of the indexing queue.
- Impelling Visibility: By actively initiating the inclusion process, you bridge the gap between resolution and results. It’s the last mile in your journey towards reinstating the visibility and accessibility of your content.
Monitoring and Maintenance: Sustaining Optimal Performance
Having traversed the terrain of issue identification, resolution, and inclusion, the voyage isn’t quite complete. The longevity of your triumph depends on vigilant monitoring and proactive maintenance. Here’s why this phase is paramount:
Ongoing Vigilance: Search engine landscapes evolve, and so do indexing dynamics. Regular monitoring using tools like Google Search Console helps you promptly identify and rectify any recurring issues.
Content Freshness: Frequent content updates not only engage your audience but also beckon search engine crawlers for recurrent visits. Freshness in content underscores the vibrancy of your digital domain.
Uninterrupted Performance: Sustained success isn’t a one-time feat but an ongoing endeavor. Consistent vigilance and maintenance uphold your website’s performance, ensuring continuous indexing and optimal visibility.
Frequently Asked Questions (FAQs)
Why are my pages not getting indexed even after being crawled?
There might be server issues, disallowed pages in “robots.txt,” or “noindex” meta tags preventing indexing.
Can I manually index pages on Google?
Yes, you can request indexing using Google Search Console.
How often should I update my website's sitemap?
It’s good practice to update your sitemap whenever you add or remove significant content.
What is the purpose of the canonical tag?
Canonical tags indicate the preferred version of a page when duplicate content exists.
Is frequent monitoring of my site necessary?
Yes, regular monitoring helps catch and address issues promptly, ensuring better indexing performance.
Are you able to fix the Google Crawling Issue?
Yes, I can fix that issue. Feel free you can reach to me to request about your any kinds of problem with SEO or Google Search Console or Google Analytics. You will find the resolution after contacting me.
Final Words
Dealing with the “Crawled – Currently Not Indexed” issue can be challenging, but with the right approach, you can regain your website’s visibility on search engine result pages. By identifying the root causes and following the steps outlined in this guide, you’ll be well on your way to resolving the issue and optimizing your website’s performance.